Top-down vs Bottom-up TDD revealed
Side note: this article is written for people which are interested in TDD and software design. It assumes that a reader is familiar with such terms as TDD Schools, Software Architecture. If you are not confident about Software Architecture then there is comprehensive set of information about it. Software architecture is very wide term, if you want to dive in it, my suggestion is book “Clean Architecture” by Uncle Bob and its essence in this article.
Much has happened since Test Driven Development methodology was coined by Kent Beck. This practice is comprehensive and as it always happens in programming was understood and implemented in various different ways. However by now there are two main approaches to TDD, formed in opposite side of the world which also are mentioned as different schools.
First of them is characterized by putting emphasis on object-oriented design, DDD, refactoring and using existing code over mocks. Was born in Detroit, and got name Detroit TDD, also sometimes it is references as Classical TDD as more mature one.
Second one is characterized by more pure and straightforward functional design, great amount of mocks in tests, and coupling to implementation. Was originated in London, and (by surprise) called London TDD, or Mockist TDD.
What about directions?
Because of differences in test design style this practices also propagate different approaches to direction or orders in which components are developed.
Because of great passion about a domain and it’s internals Classicists often start their testing road from diving into domain component (bottom), creating first tests and implementations for use cases, entities and domain logic. Then infrastructure component, and as a last step programmer climbs up to application component.
On the other hand in London TDD main idea is to start with application layer (top) as the closest layer to user, and then gradually move down to domain and infrastructure layer, implementing every needed functionality beneath.
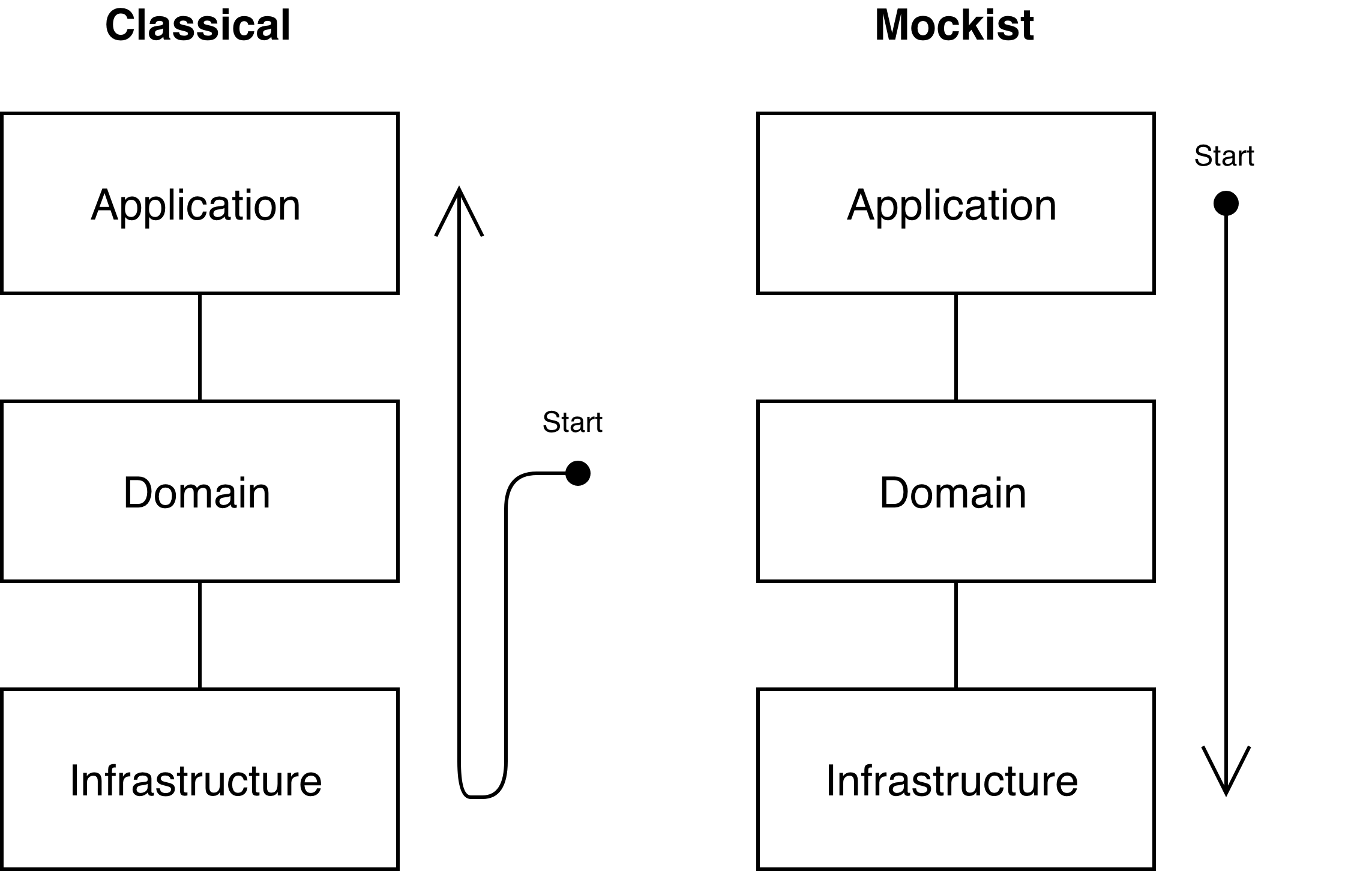
From the first look it makes no difference whether to start from domain or application layer, however entry point significantly changes your implementation. For developer that practicing TDD starting his job is associated with defining expectation for specific feature. In case of Classical approach developers begins with thinking about feature in domain point of view. The result of this is domain enrichment, great object oriented design, and enhancement of DDD practice. Mockists on the other hand think about task in terms of application and end result that is noticeable for business and users. They know how exactly their result should look like, and then go down creating only needed implementation, and therefore not breaking YAGNI.
Another point of view
However in my point of view after some explanations Detroit School of TDD can be considered top down too. Lets look at the problem slightly different, for that we have to consider some additional terms: flow of control, source code dependency and dependency inversion.
Flow of control
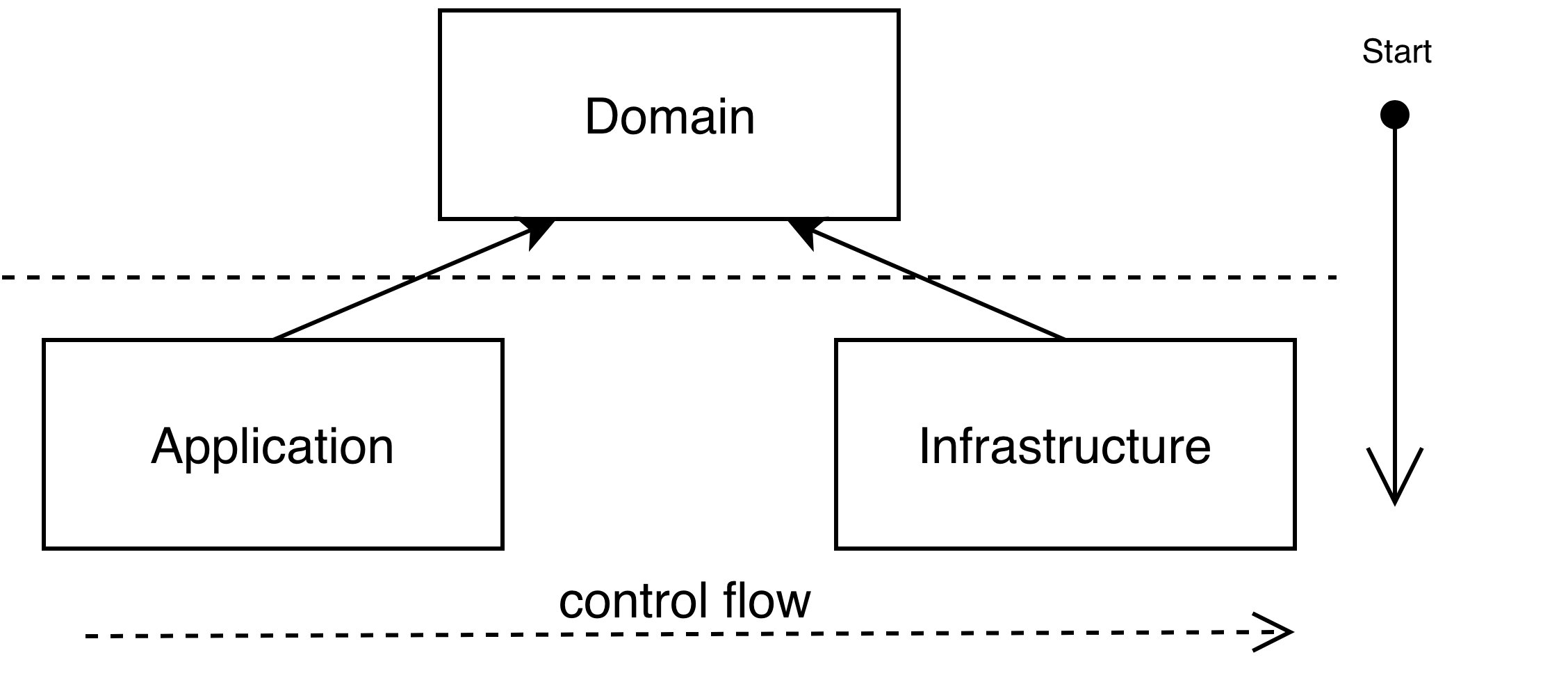
is the order in which individual statements, instructions or function calls of a program are executed or evaluated. So in typical application flow of control begins from some kind of main component or in other words entry point. It may be main function for executable programs, index files for script web languages, initial file in shell. After start flow is propagated to lower levels as depicted here:
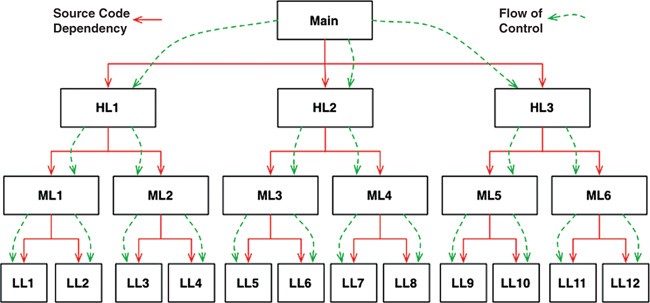
Source code dependencies vs flow of control — Martin, Robert C. 2017. Clean Architecture — A Craftsman’s Guide to Software Structure and Design. Prentice Hall. Ch. 5. Figure 5.1.
Source code dependencies
Here you can clearly see that flow of control creates so called source code dependencies - that means that higher level components depend on lower level and can’t be compiled or executed without them. This picture represents control flow and dependencies in case of layering architecture archetype. Every higher level component is coupled to component beneath it - application to domain, domain to infrastructure.
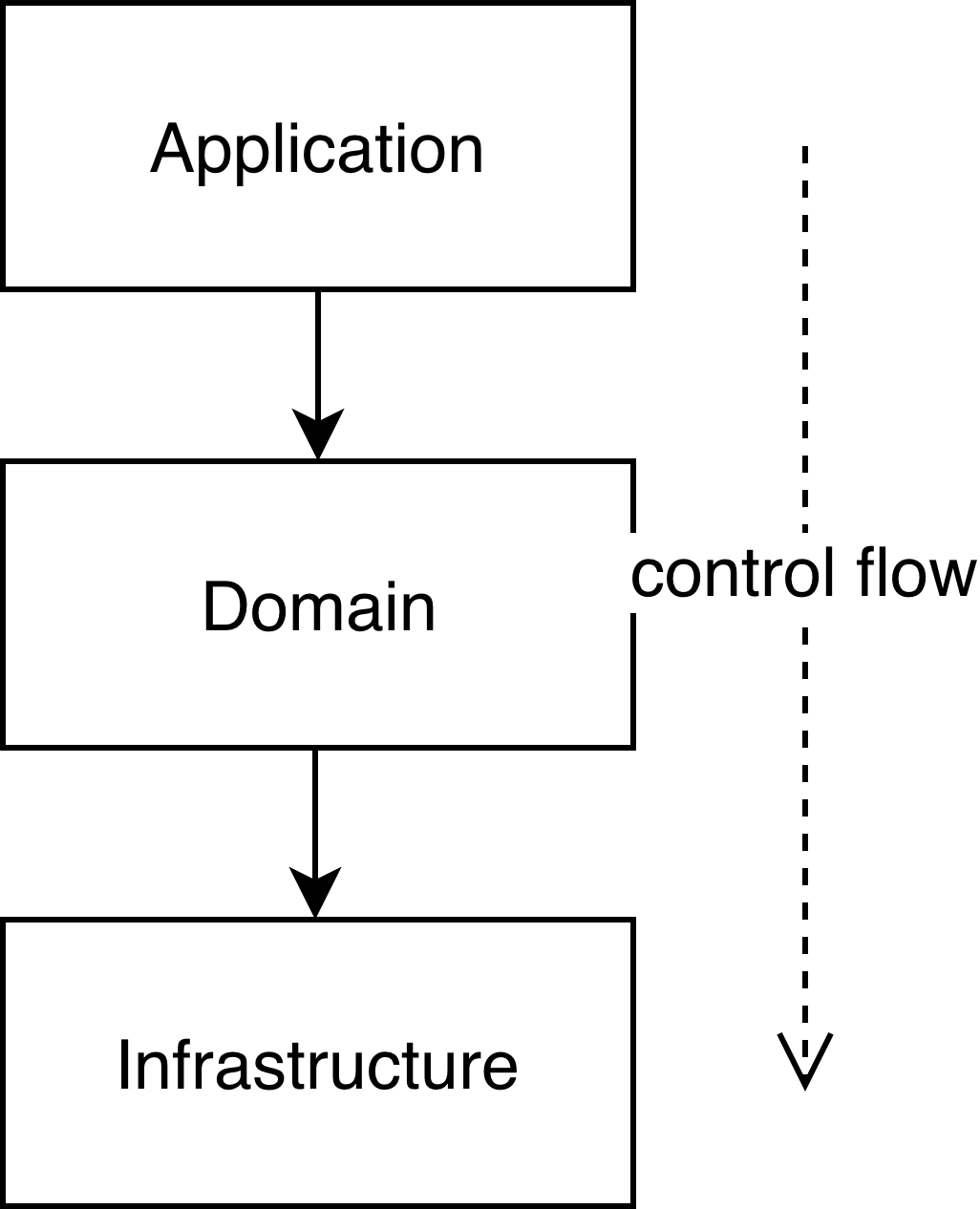
This type of coupling is very dangerous because we constantly creating dependencies from important logic to technical details. A Great example is domain layer, because of natural flow of control we introduce coupling to infrastructure - database, messaging bus, filesystem, which is undesirable for our application. How database implementation should affect business rules? In good application there is no difference. Domain should not know anything about it, to give us possibility to easily change for example database implementation or any other internals. It will give us the possibility to delay the choice as far into the future as possible, and make application more reliable, modular and therefore easier to maintain.
Dependency inversion
And there is a way to deal with such undesirable coupling in object oriented languages. It is called dependency inversion, and is achievable with polymorphism. Quintessence of its implementation lays in creating interface between higher lever and lower level component, which is shown on picture.
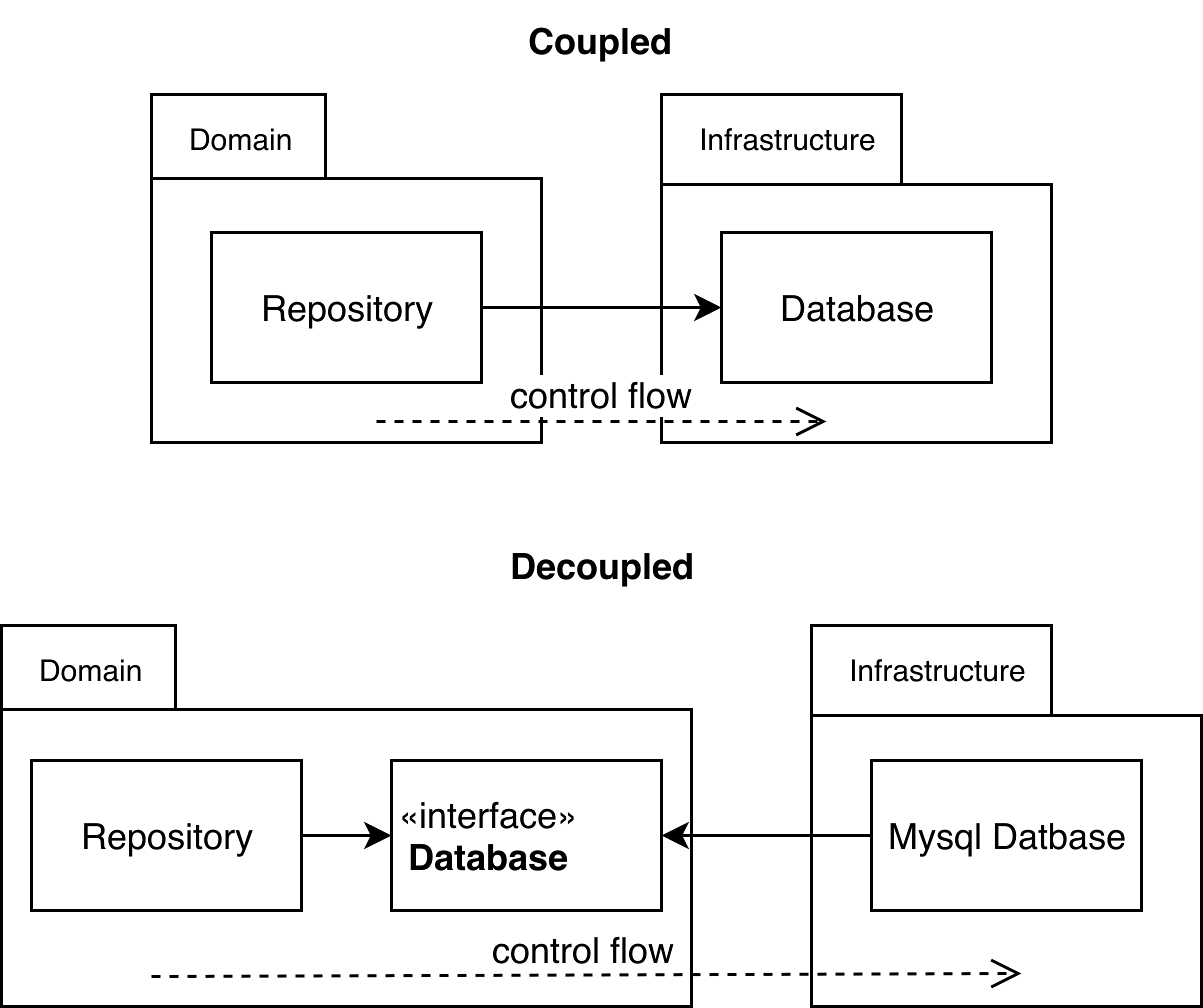
There is main advantage of this solution: the repository is not anymore coupled to concrete database, rather it defines interface that database should conform. Now we can easily swap this database, we have freedom to choose any we want. Also interesting thing that you may notice in this principle is that dependency from concrete database and database interface have opposite direction that flow of control - that’s whole idea in dependency inversion. With its help we can control dependencies direction in that way our application require.
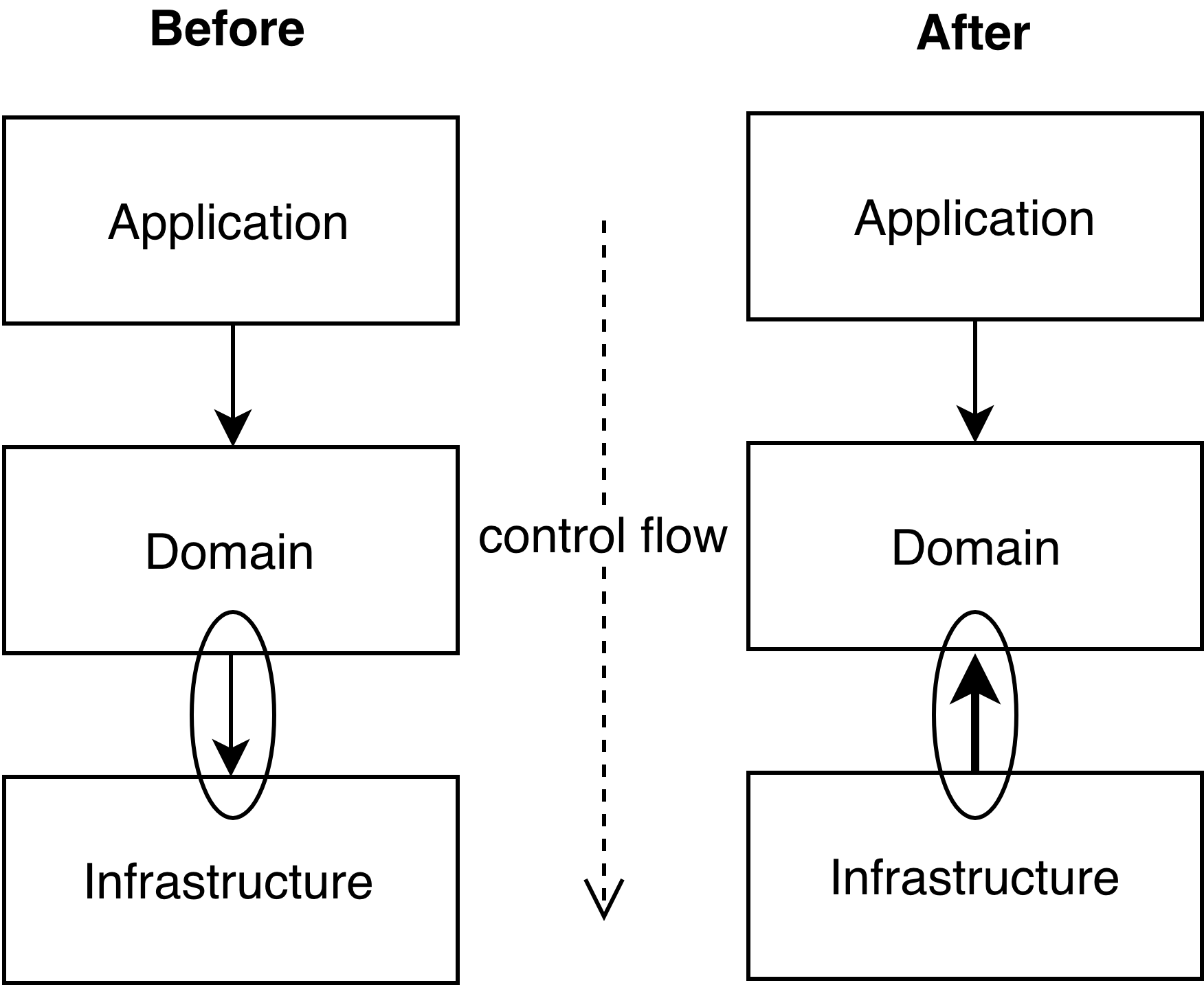
So that’s how our component model can be presented after applying dependency inversion principle to our domain component. And that’s what every engineer should do on his job - try to decouple main high-level concepts from implementation details.
Back to TDD schools
Now with all this in mind let’s apply some transformations to our component last model. And see what will happen if we will rearrange this model in dependency point of view, where domain is our high-level component and application and infrastructure are dependent upon it.
We can clearly see some interesting pattern here - if we will look at application in terms of dependencies direction and not flow of control we will see that Classical TDD development direction as straight landing from top to bottom.
Detroit TDD not climbing from details to high-level, it does just the same as London but in other dimension, trying to think in terms of software design first, starting from most and moving to less important things for our software architecture. Who knows which approach is better, but at least we can clearly see that:
- If you focus on end result and YAGNI then it’s better to choose London school.
- If you have to enhance your application architecture and domain then, perhaps Classical TDD is most suitable for you.
Related
- 23 Feb 2018 • Accelerated Mobile Pages
- 04 Oct 2017 • Gatsby — nasz nowy stack do landing page
- 09 Jun 2017 • From `sync2.php` to Continuous Delivery
License

This work is licensed under a
Creative Commons Attribution 4.0 International License
.
This means you can adapt it (even for commercial purposes), but you need to credit us by linking to
this page and share it under the same license.